如果一个数组有 10 个元素,那么这个数组下标的允许取值范围是什么?
- 对于 Fortran 语言,数组的下标取值缺省从 1 开始,且允许编程者另外指定数组下标的起始值。
- 对于 Algol 和 Pascal 语言,数组下标没有缺省的起始值,编程者必须明确指定每个数组的上下界。
- 对于标准的 Basic 语言,声明一个拥有 10 个元素的数组,实际上编译器分配了 11 个元素空间,下标范围从 0 到 10。
在 C 语言中,一个拥有 n 个元素的数组,却不存在下标为 n 的元素,它的元素的下标范围是从 0 到 n - 1。
1 | int i, a[10]; |
这段代码的本意是将数组 a 中所有的元素赋值为 0。但代码中的 a[10] 将数组 a 之后的一个字(word)的内存被设置为 0。如果用来编译这段程序的编译器按照内存地址递减的方式来给变量分配内存,那么内存中数组之后的一个字实际上是分配给了整型变量 i。此时,本来循环计数器 i 的值为 10,a[10] = 0 使得 i 的值变成 0,这就陷入了一个死循环。
尽管 C 语言的数组会让新手感到困惑,但这种特别的设计正是其最大优势所在。在常见的程序错误中,最难于发现的一类是 栏杆错误,也被称为 差一错误(off-by-one error)。
《C 专家编程》:C 语言的许多其他特性是为了方便编译器设计者而建立的。数组下标为什么从 0 开始而不是 1,因为编译器的设计者选择从 0 开始。偏移量的概念在他们心中已是根深蒂固。
100 英尺长的围栏每隔 10 英尺需要一根支撑用的栏杆,一共需要多少根栏杆呢?
如果不加思考,给出的回答很可能是 10,而正确答案是 11,这就是 栏杆错误。它经常发生在循环中的越界问题中,比如 if 中的表达式应该用小于还是小于等于?
通常,解决这类问题可以参考以下两个原则:
- 将问题简化,考虑最简单情况下的特例,然后将结果进一步外推。
- 仔细计算边界。
比如,在写遍历、插入、删除链表中元素的代码时,我们可以先考虑没有元素、只有一个元素、两个元素的情况。若代码满足这几种简单的情况,通常可以满足所有情况。
再比如,假定整数 x 满足边界条件 x >= 16 且 x <= 37,那么此范围内 x 的可能取值有多少个?千万不要因为 37 - 16 = 21,就直接认为是 21 个。正确的思路是这样的:
- 右值 - 左值 = NUM,还要加一还是减一,或是不变?
- 举出简单的情况:
x >= 16且x <= 16、x >= 16且x <= 17。 - 计算后,前者:NUM = 0,实际是 1;后者:NUM = 1,实际是 2。
- 外推:个数 = NUM + 1,有 22 个数。
为了避免这种情况的发生,我们一般用一个 下界点 和一个 上界点 来表示一个数值范围,其中 下界点 包括在取值范围之中,而 上界点 不在取值范围内。在上例中,范围应该表示为 x >= 16 且 x < 38。
这种不对称的表达方式也许从数学上而言并不优美,但是对于程序员来说,这种设计有着令人吃惊的简化效果:
- 取值范围的大小就是下界与上界之差。38 - 16 刚好等于 22,恰恰是不对称边界所包括的元素个数。
- 如果取值范围为空,那么下界等于上界,范围内个数为 0。
- 即使取值范围为空,上界也永远不可能小于下界。
C 数组下标从 0 开始就是运用了这种不对称边界的设计,此时数组的上界就是数组元素的个数。因此,本文开头的代码段应该改写成:
1 | int i, a[10]; |
另一种考虑不对称边界的方式是,把上界视作序列中第一个即将被占用的元素,而把下界视作序列中第一个即将被释放的元素,如图所示。
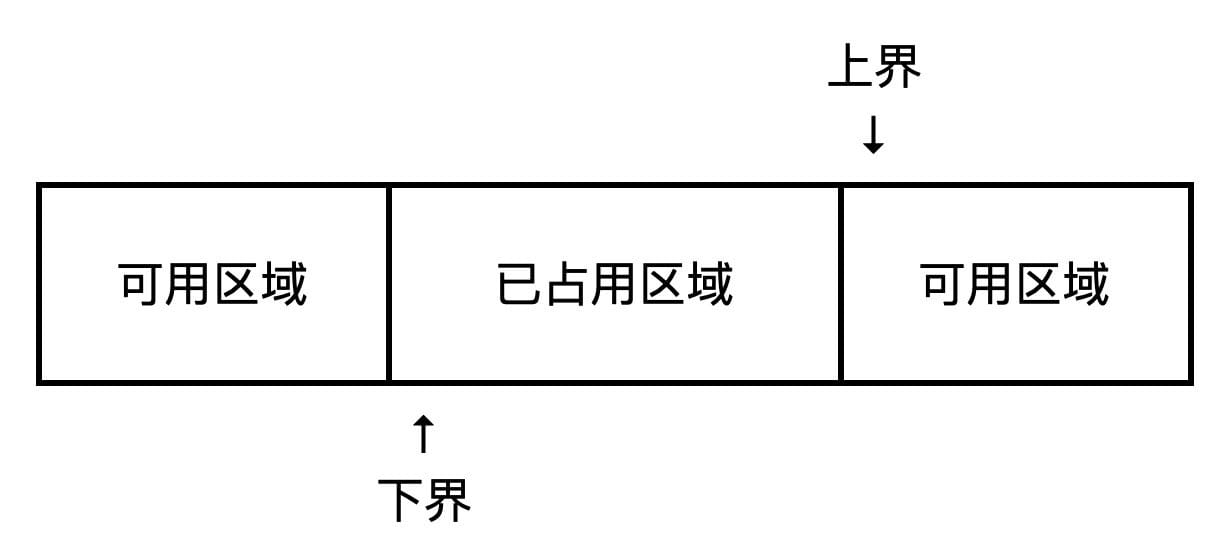
这种看待问题的方式对于处理各种不同类型的缓冲区特别有用。例如,某函数的功能是将长度无规律的输入数据送到缓冲区,每当这款内存被填满时,就将缓冲区的内容写出。缓冲区的声明如下:
1 |
|
再设置一个指针变量,指向缓冲区的当前位置:
1 | static char *bufptr; |
我们是让指针 bufptr 始终指向缓冲区中最后一个已占有的字符,还是让它指向缓冲区中之后第一个未被占用的字符?若考虑「不对称边界」的设计思想,后一种选择更为贴切。
按照「不对称边界」的思想,我们可以这样写:
1 | *bufptr++ = c; // 先进行 ++ 运算,所以递增的是 bufptr 本身的值 |
这个语句把输入字符 c 放到缓冲区中,然后指针 bufptr 递增 1,又指向缓冲区中下一个未被占用的字符。等价于:
1 | *bufptr = c; |
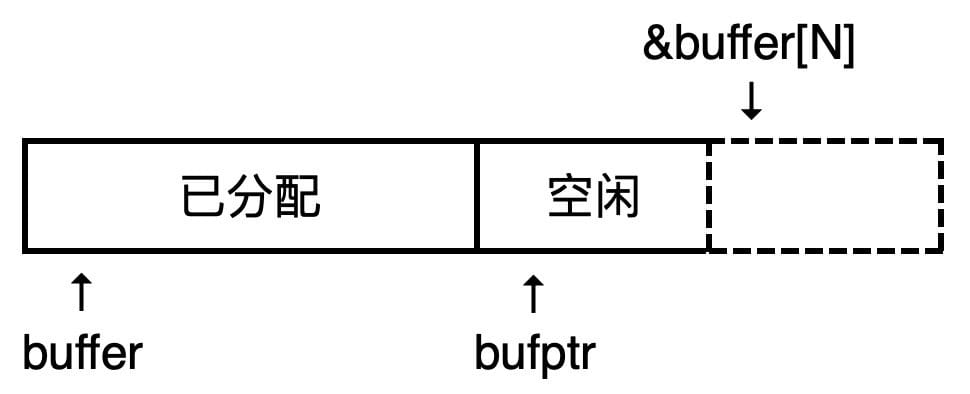
根据前面所说的第二条效果,当指针 bufptr 与 &buffer[0](或 buffer)相等时,缓冲区存放的内容为空,因此初始化时缓冲区为空可以这样写:
1 | bufptr = &buffer[0]; // 或者 buffer |
任何时候缓冲区中以存放的字符数都是 bufptr - buffer(字符类型占 1 个字节),因此我们可以通过将这个表达式与 N 进行比较,来判断缓冲区是否已满。当填满时,bufptr - buffer 就等于 N。
现在,我们写一下 bufwrite 函数:
1 | // p 指向要写入的字符串的第一个字符,n 是字符个数 |
--n >= 0 是迭代 n 次的一种写法。为了验证这一点,我们可以考察最简单的特例,即 n = 1(还记得前面说的原则吗?)。此外,--n >= 0 的效果与 n-- > 0 一样,一般前者更快(后者需要保存 n 的值,然后做递减,最后用保存的值做比较)。
值得注意的是,在 bufptr 与 &buffer[N] 的比较中,buffer[N] 这个元素根本不存在,而我们仍然使用 if (bufptr == &buffer[N]) 代替了 bufptr > &buffer[N - 1] 的写法,原因在于我们要坚持「不对称边界」的原则:我们要比较指针 bufptr 与 缓冲区后一个字符的地址(即上界),而 &buffer[N] 就是这个地址。
在此,我们并不需要引用一个不存在的元素,而只需要引用这个元素的地址。我们需要保证不对该引用解引,而且在 C 语言中这个地址是的确存在的(ANSI C 标准明确允许这种用法)。
最后,改进程序,使得它可以一次移动 k 个字符:
1 | void memcpy(char *dest, const char *source, int k) { |
1 | void bufwrite(char *p, int n) { |
解释见注释。
以上就是不对称边界的两种应用方式。
参考:《C 陷阱与缺陷,C Traps and Pitfalls》P45(边界计算与不对称边界)