系统级 I/O
什么是输入/输出?(估计很多人都说不清楚!)
输入/输出(I/O)是在主存和外部设备(磁盘驱动器、终端、网络等)之间复制数据的过程。其中:
输入操作是从 I/O 设备复制数据到主存输出操作是从主存复制数据到 I/O 设备
Unix I/O
一个 Linux 文件就是一个 m 个字节的序列:
$$
B_0, B_1, \cdots, B_k, \cdots, B_{m-1}
$$
所有的 I/O 设备都被模型化文件,而所有的输入和输出都被当作对相应文件的读和写来执行。这种将设备优雅地映射为文件的方式,允许 Linux 内核引出一个简单、低级的应用接口,称为Unix I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行:
- 打开文件。一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个 I/O 设备。内核返回一个小的非负整数,叫做
描述符,它在后续对此文件的所有操作中标识这个文件。 - Linux shell 创建的每个进程开始时都有三个打开的文件:
标准输入(描述符为 0)、标准输出(描述符为 1)、标准错误(描述符为 2)。 - 改变当前的文件位置、读写文件、关闭文件等。
文件
每个 Linux 文件都有一个类型(type)来表明它在系统中的角色:
普通文件(regular file):包含任意数据。应用程序常常要区分文本文件(text file)和二进制文件(binary file),文本文件是只含有 ASCII 或 Unicode 字符的普通文件;二进制文件是所有其他文件。对内核而言,文本文件和二进制文件没有区别。Linux 文本文件还包含了一个文本行(text line)序列,其中每一行都是一个字符序列。目录(directory):包含一组链接(link)的文件,其中每个链接都将一个文件名映射到一个文件(注意这个文件可能又是另一个目录)。每个目录至少有两个文件(.、..)。套接字(socket):用来与另一个进程进行跨网络通信的文件。- 其他类型:
命名通道(named pipe)、符号链接(symbolic link)、字符和块设备(character and block device)。
共享文件
可以用许多不同的方式共享 Linux 文件。除非你很清楚内核是如何表示打开文件,否则文件共享的概念相当难懂。内核用三个相关的数据结构来表示打开的文件:
描述符表(descriptor table):每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。文件表(file table):打开文件的集合是由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项组成包括当前的文件位置、引用计数(reference count),以及一个指向 v-node 表中对应表项的指针。关闭一个描述符会减少相应的文件表项中的引用次数。当引用次数为零时,内核会删除这个文件表表项。v-node 表(v-node table):同文件表一样,所有的进程共享这张 v-node 表。每个表项包含了 stat 结构中的大多数信息,包括st_mode和st_size成员。
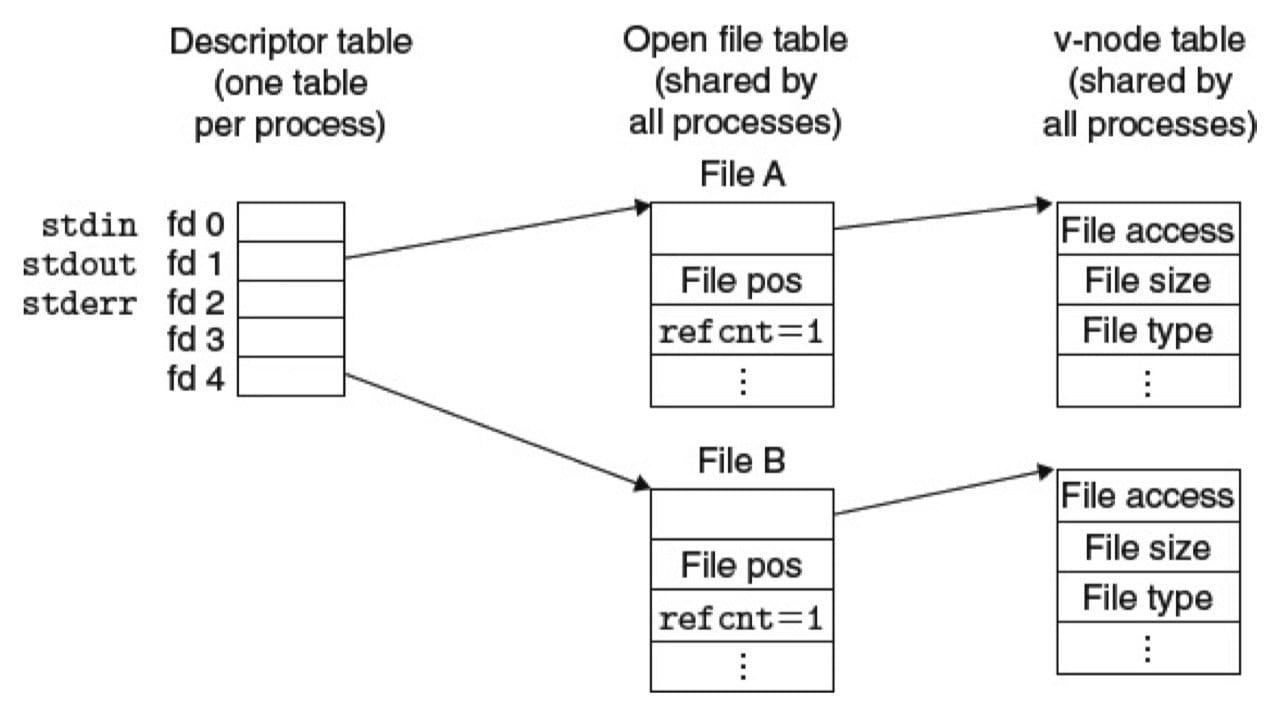
在这个示例中,两个描述符引用不同的文件,没有共享。
多个描述符也可以通过不同的文件表表项目来引用同一个文件。例如,如果以同一个 filename 调用 open 函数两次。关键思想是每个描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取数据。(是指同一个文件的不同位置?)
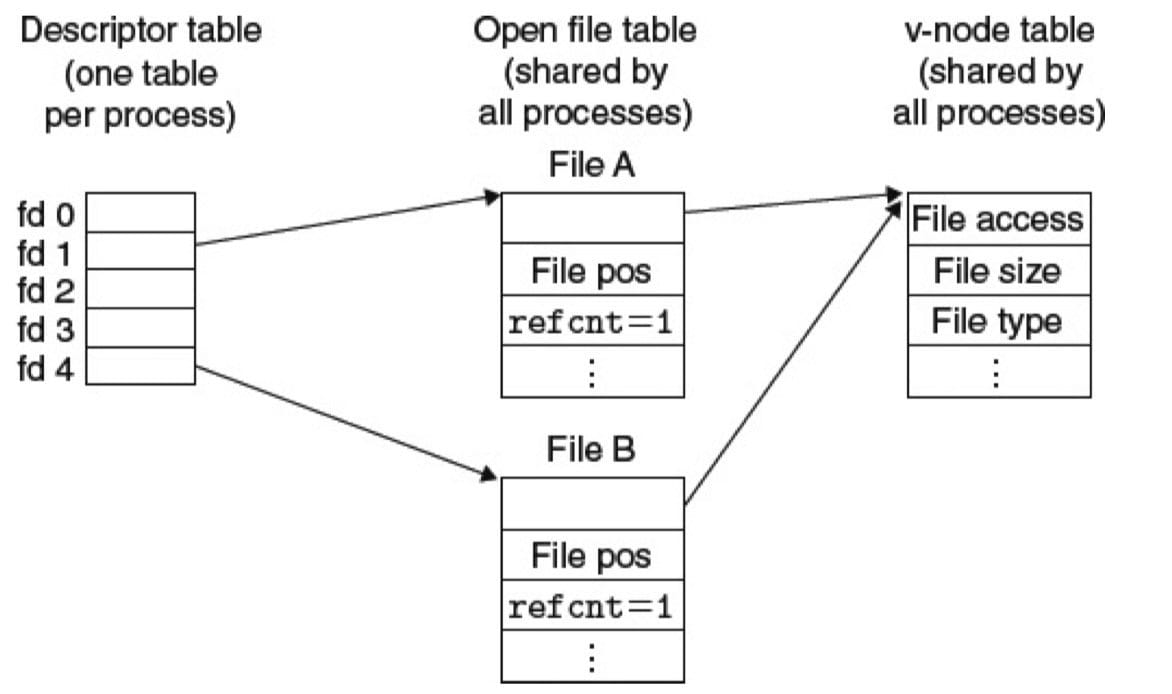
这个例子展示了两个描述符通过两个打开文件表表项共享同一个磁盘文件。
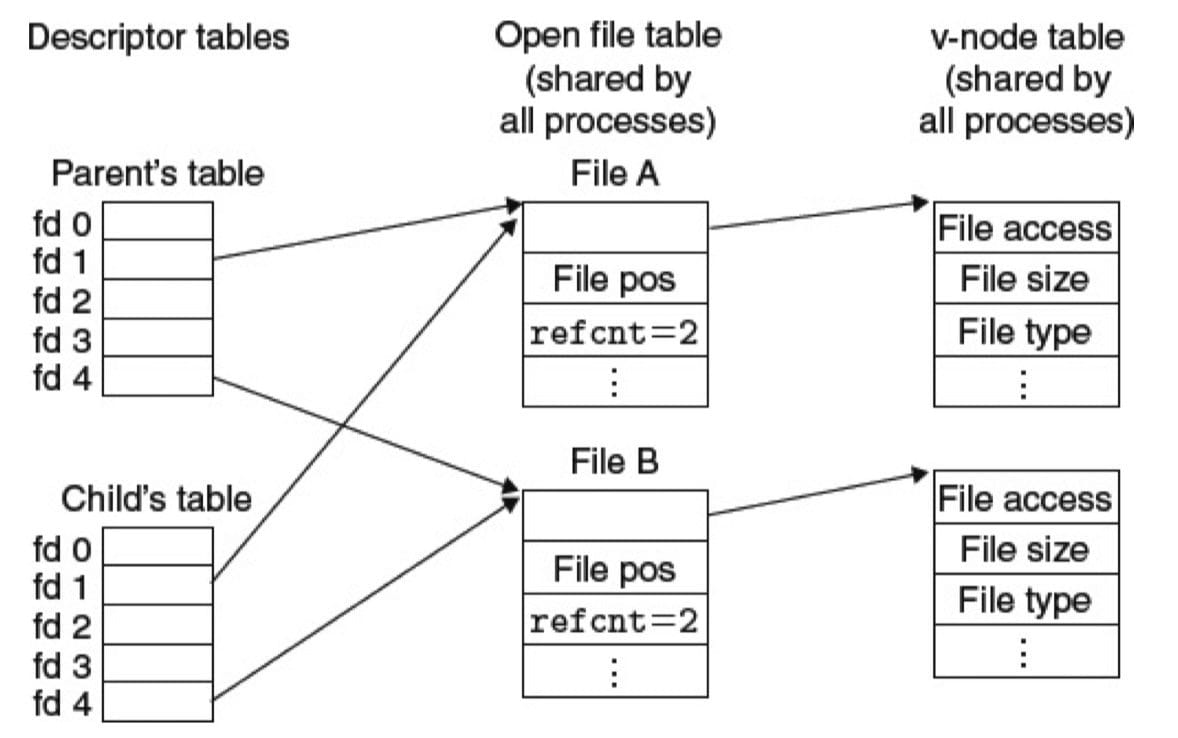
我们也可以理解父子进程是如何共享文件的。假设在调用 fork 之前,父进程有如图 10-12 所示的打开文件。然后,图 10-14 展示了调用 fork 后的情况。子进程有一个父进程描述符表的副本。父子进程共享相同的打开文件表集合,因此共享相同的文件位置。一个很重要的结果是,在内核删除相应文件表表项之前,父子进程必须都关闭了它们的描述符。
标准 I/O
C 语言定义了一组高级输入输出函数,称为标准 I/O 库,为程序员提供了Unix I/O的较高级别的替代。标准 I/O 库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向FILE类型的结构的指针。每个 ANSI C 程序开始时都有三个打开的流 stdin、stdout 和 stderr。
网络编程
客户端-服务器编程模型
每个网络应用都是基于客户端-服务器模型的。采用这个模型,一个应用是由一个服务器进程和一个或者多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源为它的客户端提供某种服务。
客户端-服务器模型中的基本操作是事务(transaction)。该事务没有数据库事务的任何特性。一个客户端-服务器事务由以下四步组成:
- 当一个客户端需要服务时,它向服务器发送一个
请求,发起一个事务。 - 服务器收到
请求后,解析它,并以适当的方式操作它的资源。 - 服务器给客户端发送一个
响应,并等待下一个请求。 - 客户端收到
响应并处理它。
注意:认识到客户端和服务器是进程,而不是常提到的机器或者主机,这是很重要的。
网络
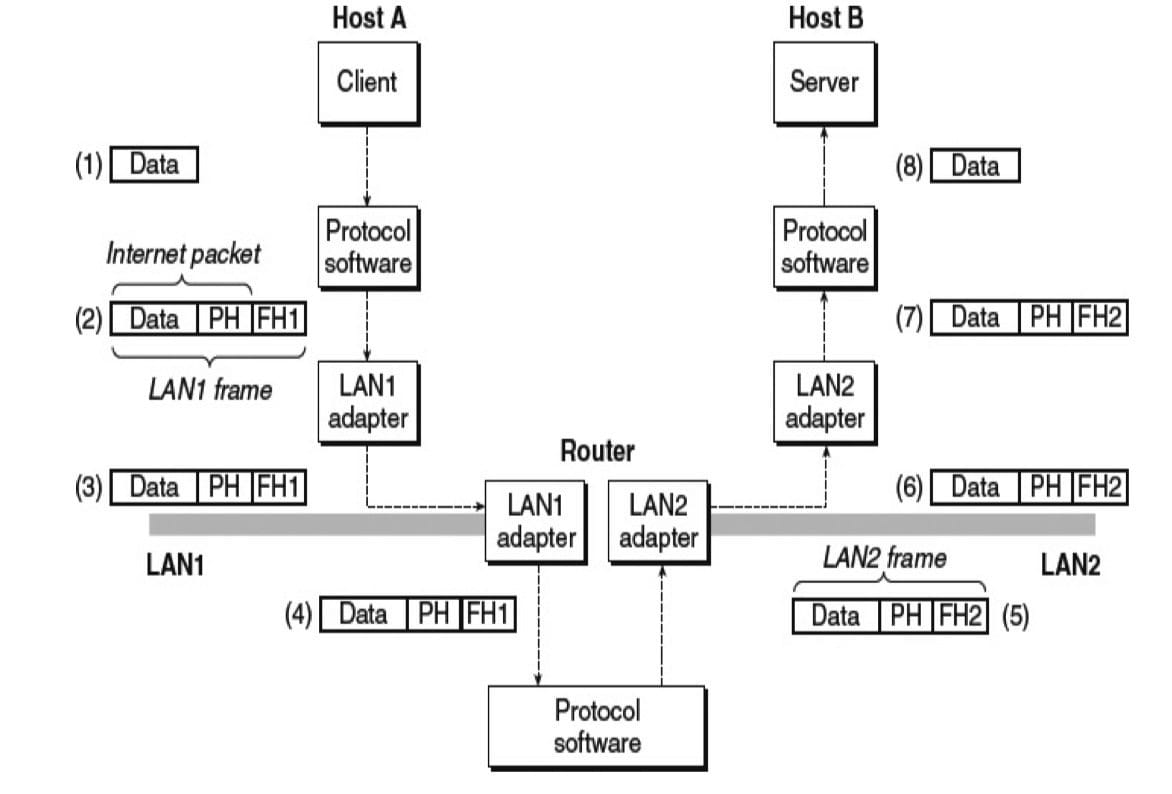
如果不同的网络有不同的帧大小的最大值,该怎么办?路由器如何知道该往哪里转发帧呢?当网络拓扑变化时,如何通知路由器呢?如果一个包丢失了又会如何呢?虽然如此,这个示例抓住了互联网络思想的精髓,封装是关键。
全球 IP 因特网
全球 IP 因特网是最著名和最成功的互联网络实现。
因特网是政府、学校和工业界合作的最成功的示例之一。
因特网的发展历史(挺有趣的):p652,起源于美国政府实行的高级研究计划署ARPA中的 ARPANET项目。
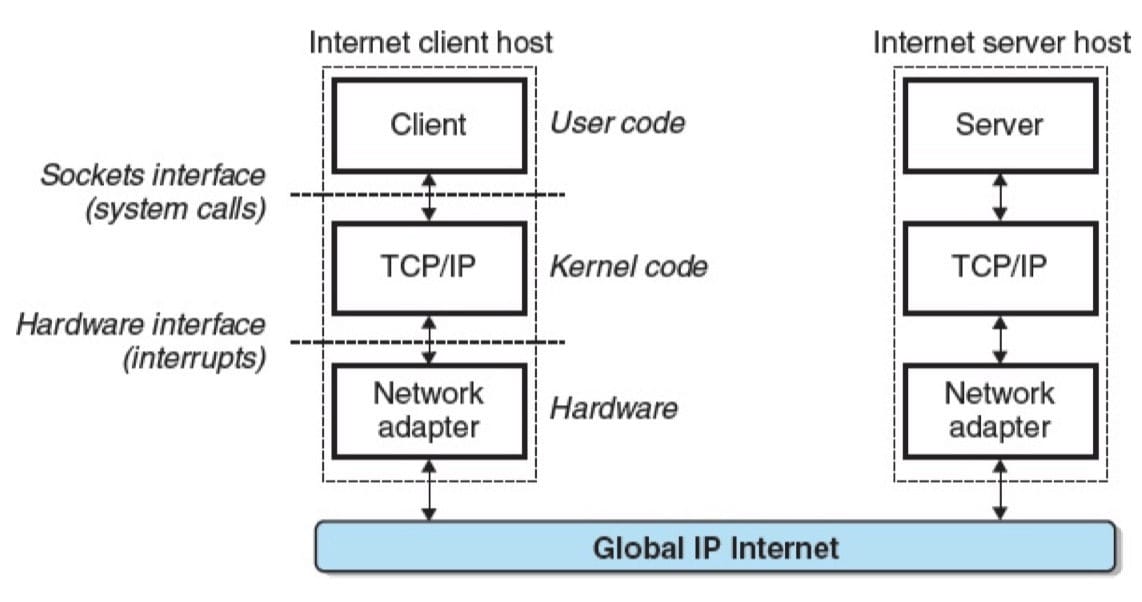
因特网的客户端和服务器混合使用套接字接口函数和Unix I/O函数来进行通信。通常将套接字接口函数实现为系统调用,这些系统调用会陷入内核,并调用各种内核模式的 TCP/IP 函数。
IP 地址
一个 IP 地址是一个 32 位无符号整数。网络程序将 IP 地址存放在 IP 地址结构中。
1 | /* IP address structure */ |
把一个标量地址存放在结构中,是套接字接口早期实现的不幸产物。为 IP 地址定义一个标量类型应该更有意义,但是现在更改已经太迟了。TCP/IP 为任意整数数据项定义了统一的网络字节顺序(network byte order)(大端字节顺序),即使主机字节顺序(host byte order)是小端法。
套接字接口
一个套接字是链接的一个断点。每个套接字都有相应的套接字地址,是由一个因特网地址和一个 16 位的整数端口组成的,用地址: 端口来表示。
当客户端发起一个连接请求时,客户端套接字地址中的端口是由内核自动分配的,称为临时端口(ephemeral port)。然而,服务器套接字地址中的端口号通常是某个知名端口,是和这个服务对应的,记录在/etc/services。
一个连接是由它两端的套接字地址唯一确定的。这对套接字地址叫做套接字对(socket pair),由元组表示:(cliaddr:cliport, servaddr:servport)。

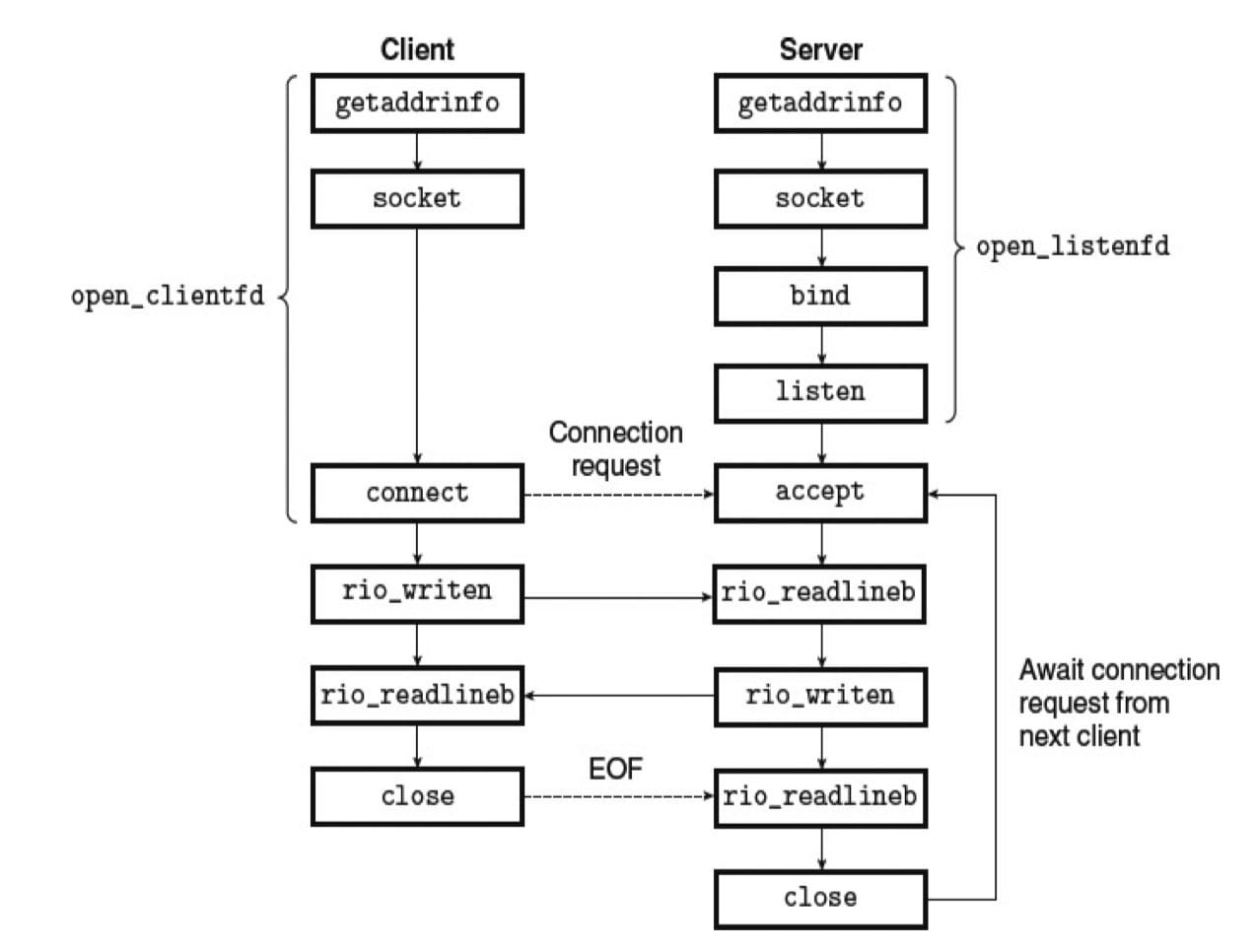
起源
套接字接口是加州大学伯克利分校的研究人员在 20 世纪 80 年代早期提出的,所以也叫做伯克利套接字。
从 Linux 内核的角度来看,一个套接字就是通信的一个端点。从 Linux 程序的角度来看,套接字就是一个有相应描述符的打开文件。
1 | /* IP socket address structure */ |
定义套接字函数要求一个指向通用 sockaddr 结构的指针,然后要求应用程序将与协议特定的结构的指针强制转换成这个通用结构。
参考:p654 有各种函数
参考:p665 万维网的起源(Tim Berners-Lee 在欧洲粒子物理研究所发明的;随后在 1993 年 Marc Andreesen【后来创建了 Netscape】和同事在 NCSA 发布了一种图形化的浏览器,叫做 MOSAIC,使 Web 网站彻底火了)