ADTs
An Abstract Data Type (ADT) is defined only by its operations (behaviors), not by its implementation.

Note: Swap the removed item with the the last item, and remove the last item. It makes remove() faster.
Among the most important interfaces in the java.util library are those that extend the Collection interface:
- Lists of things
- Sets of things
- Mappings between items
- Maps also known as associative arrays, associative lists (in Lisp), symbol tables, dictionaries (in Python).
BST
Binary Search Trees
Basics of Tree
A tree consists of:
- A set of
nodes(keys & values). - A set of
edgesthat connect nodes.- Constraint: There is exactly one path (may contain several edges) between any two nodes. No cycle.
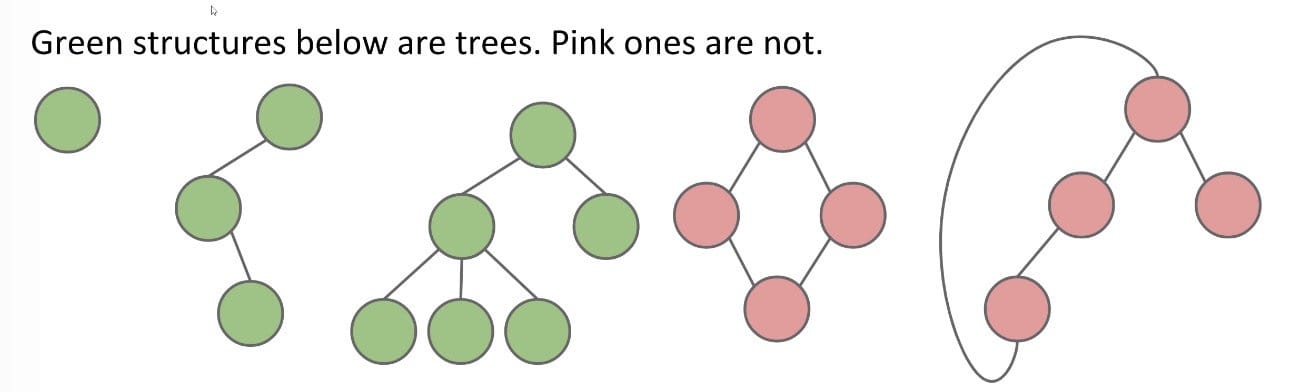
In a rooted tree, we call one node the root.
- Every node except the root has exactly one
parent. - A node with no child is called a
leaf. - Binary Tree: Every node has either 0, 1, or 2 children (subtrees).
Definition (BST)
The BST is one of the most important ideas that you’ll ever learn in all of computer science.
Can think of the BST as representing a Set (keys) or even a Map (keys and values).
A linked list is great, but it takes a long time to search for an item, even if the list is sorted! If the item is at the end of the list, that would take linear time.

Fundamental Problem: Slow search, even though it’s in order.
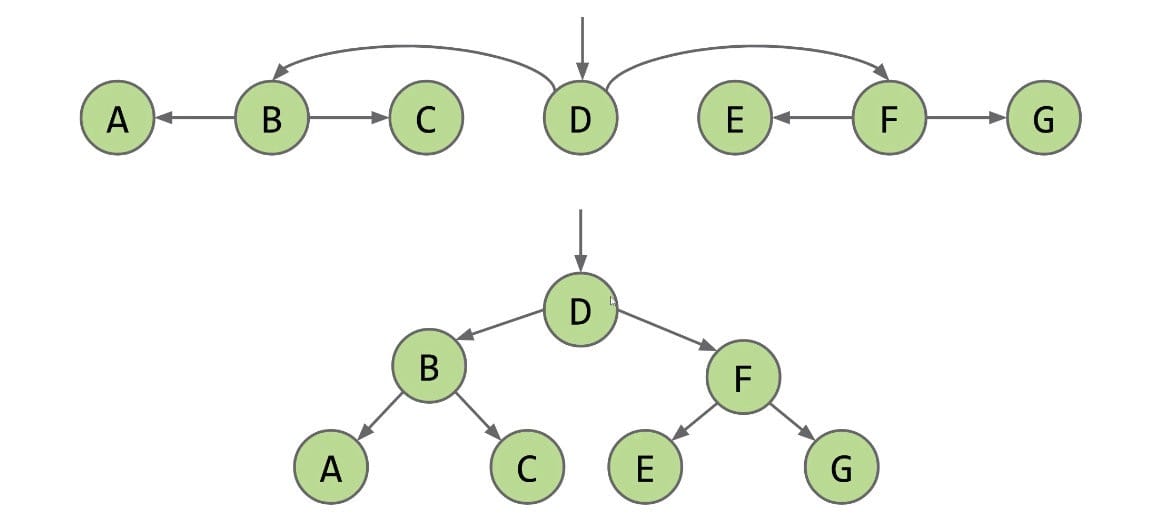
Definition: A binary search tree is a rooted binary tree with the BST property.
- Every key in the
leftsubtree islessthan X’s key. - Every key in the
rightsubtree isgreaterthan X’s key.
Ordering
Ordering must be complete, transitive, and antisymmetric. Given keys $p$ and $q$:
- Exactly one of $p \prec q$ and $q \prec p$ is true (not both).
- $p \prec q$ and $q \prec r$ imply $p \prec r$. (transitive)
An example of not complete: Family tree. Compared to your parents, you are “less than”; but compared to your cousins, there is no answer and it’s not a complete thing (in different branches).
One consequence of these rules: No duplicate keys allowed!
It keeps things simple. Most real world implementations follow this rule.
1 | private class BST<Key> { |
- For a BST that is
bushy(short and fat), we can search in $O(\log N)$ time where $N$ is the number of nodes. - For a BST that is
spindly(tall and skinny), our search will take $O(N)$ time.
Operations
algs4: BST.java
BST Class
1 | public class BST<Key extends Comparable<Key>, Value> { |
Search/Get
1 | /** get */ |
Iterative version:
1 | /** get */ |
1 | /* exist - return boolean */ |
Insert/Put
Search for key:
- If found, do nothing
- If not found:
- Create new node
- Set appropriate link
We always insert at a leaf node!
Do not write code like:
1 | if (T.left == null) T.left = new BST(key); |
Recursive version (+ size):
If we need to change the BST, write a helper function that return s a Node object.
1 | public void put(Key key, Value val) { |
My Code (not good):
Haha! This is the first time I write
insert!
1 | public static void insert(BST T, Key sk) { |
Iterative version (no size):
1 | public void putIter(Key key, Value val) { |
Delete
Consider the following three cases of node $x$:
Case 1: No children
Just sever the parent’s link, and the deleted node will be garbage collected.
In code, this means
return null.Case 2: Has 1 child
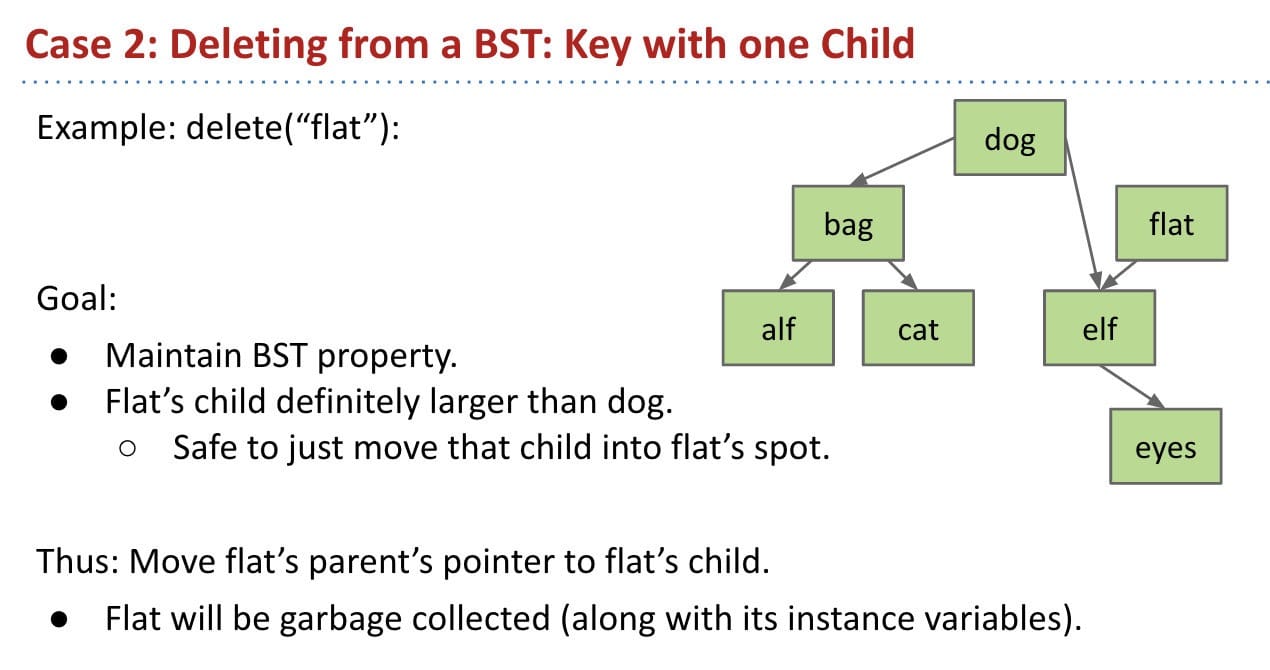
We can use recursion to avoid pointer backup.
What about deleting the root?
Case 3: Has 2 children
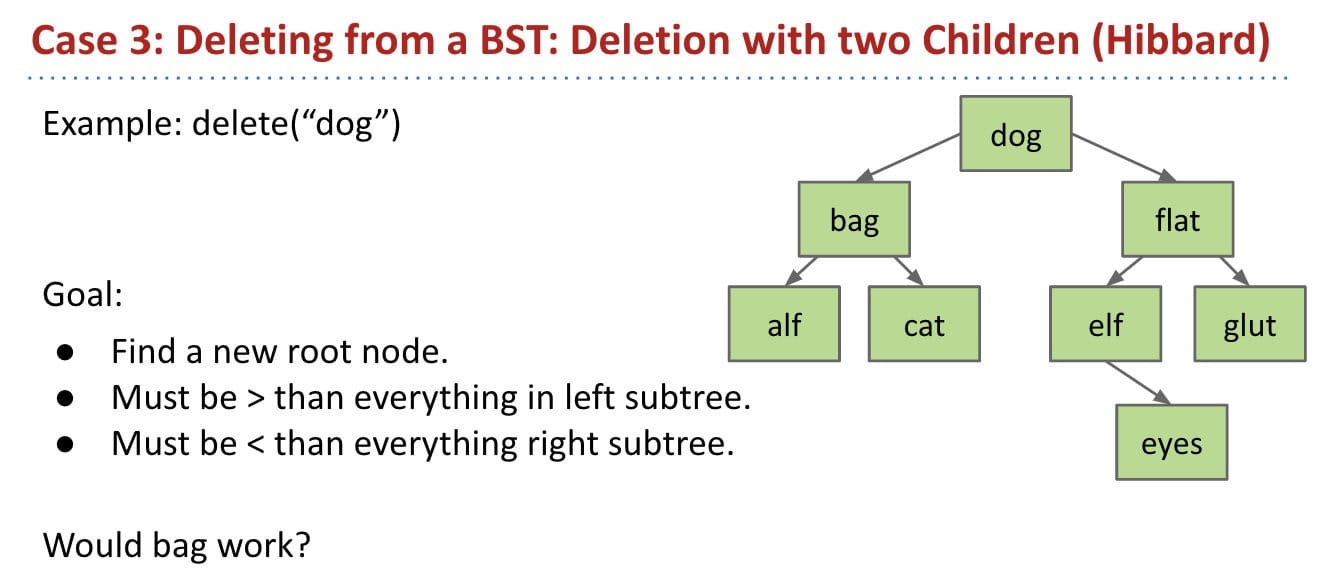
No. Moving “bag” is not a good idea.
We can choose either
predecessor "cat"orsuccessor "elf".In other words,
catis the largest node in the left tree;elfis the smallest node in the right tree.Delete
catorelf, and stick new copy in the root position: This deletion guaranteed to be either case 1 or 2 (no two children). Why?- Reason: Predecessor or successor has only one child or no children.
This method is known as
Hibbard deletion.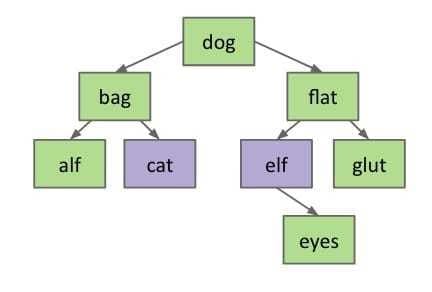
For example, delete
dogand moveelfto the root; since we need to deleteelfeither,eyeswill be the left child offlat(case 1).
1 | // dog |
1 | /** delete */ |
Or using min and deleteMin in algs4:
[BST.java](https://github.com/junhaowww/algs4/blob/master/ch3-searching/src/BST.java)
DeleteMin
1 | public void deleteMin() { |
Floor
1 | /** floor */ |
Select
1 | // 4 |
Rank
1 | // 4 |
Range Searching
Note: Consider each subtree as $x$.
1 | /** |
Lab 7 (BSTMap)
Lab 7: BSTMap.java & Map61B.javaAlgs: BST.java
numberOfNodes(BSTMap b)$\sim \Theta(n)$ (b has $n$ nodes)
z is a positive integer.
What is the running time (in Big O notation) of mystery(b, z)?
1 | public Key mystery(BSTMap b, int z) { |
Time: $O(\log{N})$ where $N$ is the number of nodes in $b$.
Ex (Discussion & Guide)
C Level
Ex 1 (Orderings)
Give two orderings of the keys A X C S E R H that, when inserted into an empty BST, yield the best case height. Draw the tree.
In order: A C E H R S X
H - C - S - …
H - S - C - …
B Level
Ex 1 (Valid Sequence)
Suppose that a certain BST has keys that are integers between 1 and 10, and we search for 5. Which sequence(s) of keys below are possible during the search for 5?
Each time one level, no backward.
a. 10, 9, 8, 7, 6, 5 (o)
b. 4, 10, 8, 7, 5 (o)
c. 1, 10, 2, 9, 3, 8, 4, 7, 6, 5 (o) a chain
d. 2, 7, 3, 8, 4, 5 (x) 8 > 7
e. 1, 2, 10, 4, 8, 5 (o)
Ex 2 (Commutative)
Is the delete operation commutative? In other words, if we delete $x$, then $y$, do we always get the same tree as if we delete $y$, then $x$?
Maybe yes! Couldn’t think of any case. Me reviewing: Couldn’t find it again.
Ex 3 (#Children)
Problem 1 from the Fall 2014 midterm #2.

- Either 0 or 2 not-null children (complete tree) - $O(\log N)$
- Either 0 or 2 children - $O(N)$
- Either 0 or 1 child - $O(N)$
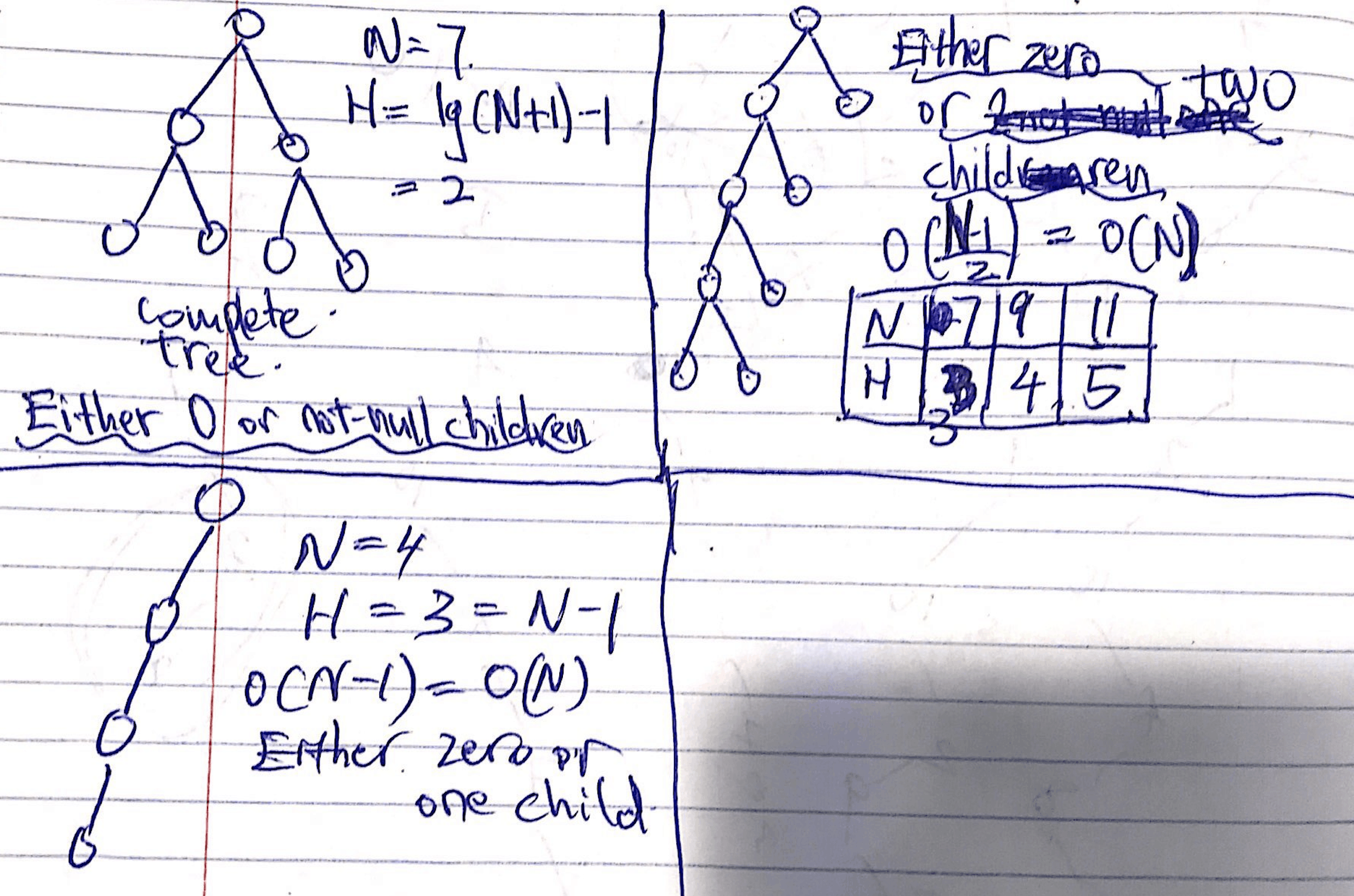
A+ Level
Ex 1 (Merge)
Problem 3 from the Fall 2009 midterm.
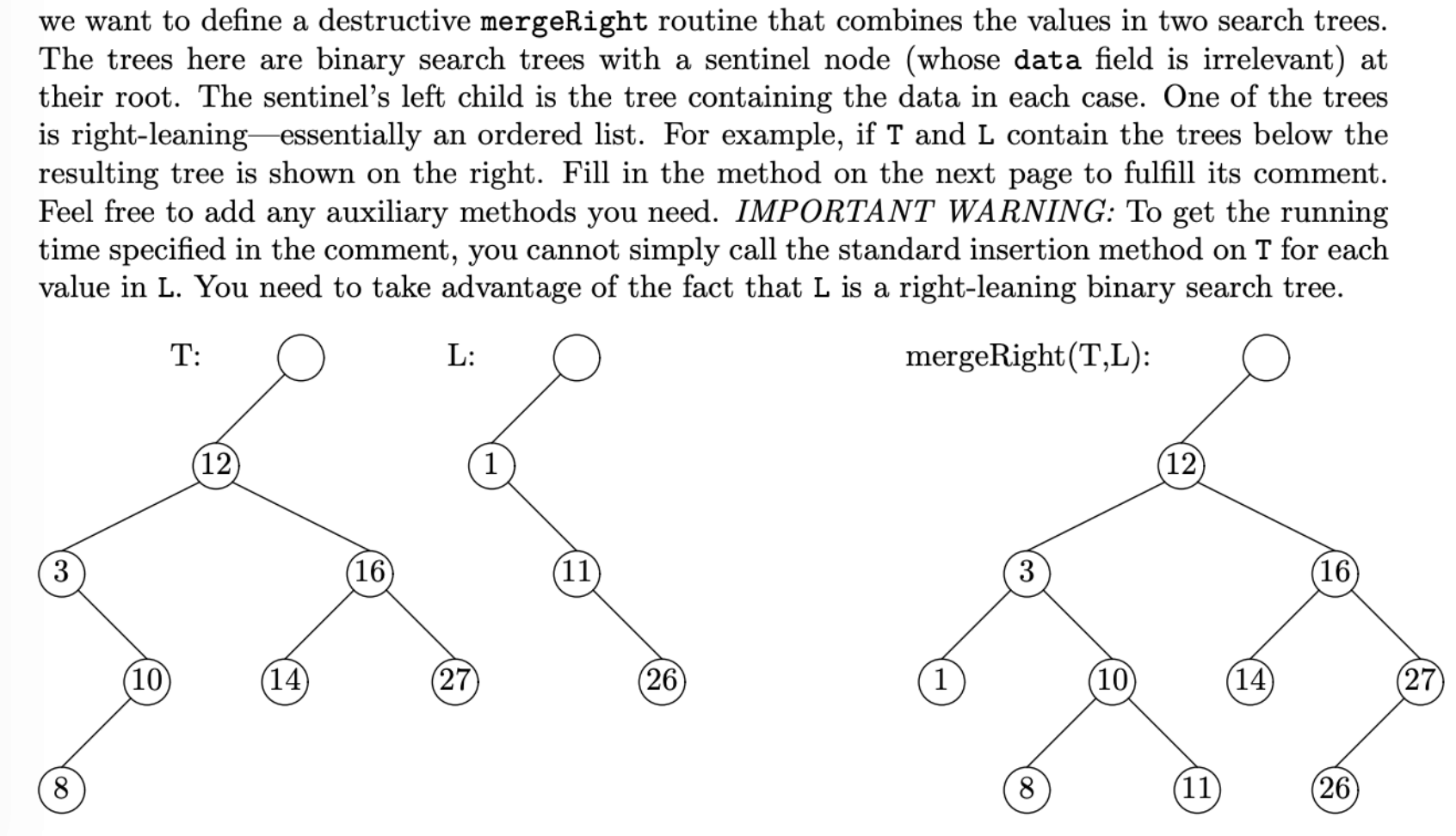
1 | /* The operation is [destructive], and creates no new nodes. |
I think the worst case is $O(L \log{T})$
Ex 2 (Is Valid BST?)
From Discussion 7, Spring 2019.
Buggy version:
1 | class TreeNode { |
The code just looks at two levels.
Example:
1 | // 5 |
Bug-free version:
1 | public static boolean isBST(TreeNode T) { |
Challenge Lab 7
Challenge Lab 7: link
Code: link
The Internal Path Length of a BST is defined as the average depth times the number of nodes. Or equivalently, it is the sum of the lengths of the paths to every node. The internal and external path lengths are related by:
$$E = I + 2n$$
where $n$ is the number of internal nodes.
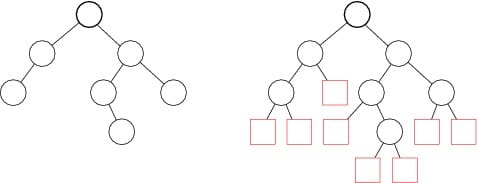
Implementation of OIPL:
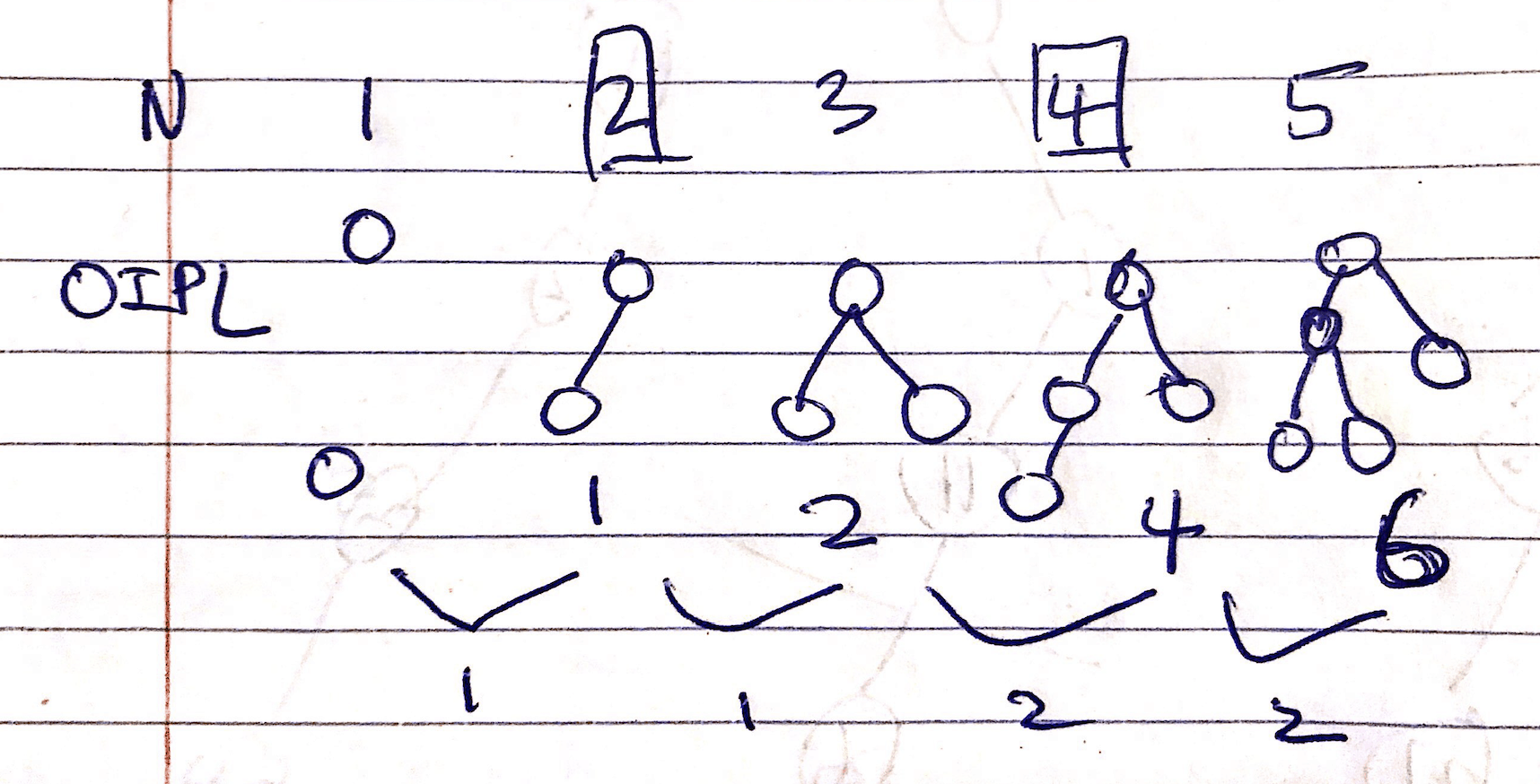
1 | /** |
Reference: Research Problem about Average Depth
Randomly picking between successor and predecessor will result in 88% of the starting depth. Nobody knows why this happens.