Reference:
- Huahua SP5 Binary Search (video)
- Huahua SP17 Binary Search II (video)
- 二分查找、二分边界查找算法的模板代码总结 (not really helpful)
Binary Search
Binary Search is a basic technique for programmers. The problems it covers are usually examined by interviewers.
Why Binary Search?
- Fast: $T(N) = T(N/2) + O(eval)$, where $O(eval)$ could be $O(1)$, $O(\log{N})$, $O(N)$, or $O(N\log{N})$.
- Linear Scan: $O(range) \times O(eval)$
- Binary Search: $O(\log{(range)}) \times O(eval)$
According to the input scale, we have the following estimates (from the video):
| Range | Binary (s) | Linear (s) | Speed Up (x) |
|---|---|---|---|
| 100 | 7 | 100 | 14.29 |
| 10,000 (10K) | 14 | 10,000 | 714.29 |
| 1,000,000 (1M) | 20 | 1,000,000 | 50000.00 |
| 1,000,000,000 (1B) | 30 | TLE | N/A |
When Do We Use Binary Search?
- The array is
partiallyorfullysorted. - The upper bound of time complexity is $O(N)$ or $O(\log{N})$.
There are many variants of binary search. We should be careful of loop condition, mid/left/right update, and return value. Although we may always return lo, some problems may require lo - 1.
As you can see in 162. Find Peak Element, the loop condition and right update are not common.
Intervals
Three Common Intervals
[lo, hi): Left-closed Right-open (C++ STL Stylebegin(), end())[lo, hi]: Left-closed Right-closed (can avoid overflow ifhiis the largest integer)(lo, hi): Left-open Right-open (not common)
There is no difference in terms of their outputs if they implement the idea that:
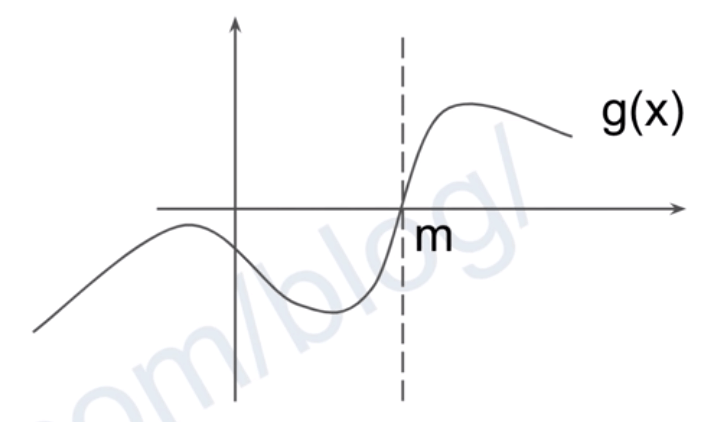
- Given a function
g(mid), returns the smallestmidin the range such thatg(mid)holdstrue. Don’t think in a way of going to the left or right like we do in binary search trees.
The internal representation could be off by $1$ or $2$, but the final output should be exactly the same. Check out the internal examples below.
When could we use binary search?
For function g(mid), there exists a point mid such that:
g(mid)holds true ifx >= mid(at least onexor allxs).g(mid)holds false ifx < mid.
Note: In the peak example above, when x >= mid, g(mid) == true is guaranteed for at least one x.
Thus, only when g(mid) has this property can we use binary search.
The key to binary search is DON’T try to find the exact answer (e.g. don’t write code like if (mid == val) return mid;), but find a split point mid such that x >= mid holds true for all or at least one x, then mid will naturally become the answer. You can see later that it could also give us the lower bound (leftmost) index of the value.
Besides, it is a good way to avoid boundary errors. If you return the answer directly (standard binary search), your code will be erroneous with high probability.
Left-closed Right-open [lo, hi):
1 | public void binarySearch(int lo, int hi) { |
Left-closed Right-closed [lo, hi]:
1 | public void binarySearch(int lo, int hi) { |
Internal Examples
Reference: From the video
a. Search range is [10, 101], g(mid) = true if mid >= 25; Else g(mid) = false.
[lo, hi) vs. [lo, hi]:
| Iteration | lo | hi | mid | g(mid) | lo | hi | mid | g(mid) |
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 102 | 56 | true | 10 | 101 | 55 | true |
| 2 | 10 | 56 | 33 | true | 10 | 54 | 32 | true |
| 3 | 10 | 33 | 21 | false | 10 | 31 | 20 | false |
| 4 | 22 | 33 | 27 | true | 21 | 31 | 26 | true |
| 5 | 22 | 27 | 24 | false | 22 | 25 | 23 | false |
| 6 | 25 | 27 | 26 | true | 24 | 25 | 24 | false |
| 7 | 25 | 26 | 25 | true | 25 | 25 | 25 | true |
| 8 | 25 | 25 | - | - | 25 | 24 | - | - |
Notice the ending state lo == hi vs. lo > hi.
We can see that although g(mid) holds true, we don’t return immediately. We want to locate at the lower bound.
b. Search range is [10, 101], g(mid) = true if mid >= 120; Else g(mid) = false.
[lo, hi) vs. [lo, hi]:
| Iteration | lo | hi | mid | g(mid) | lo | hi | mid | g(mid) |
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 102 | 56 | false | 10 | 101 | 55 | false |
| 2 | 57 | 102 | 79 | false | 56 | 101 | 78 | false |
| 3 | 80 | 102 | 91 | false | 79 | 101 | 90 | false |
| 4 | 92 | 102 | 97 | false | 91 | 101 | 96 | false |
| 5 | 98 | 102 | 100 | false | 97 | 101 | 99 | false |
| 6 | 101 | 102 | 101 | false | 100 | 101 | 100 | false |
| 7 | 102 | 102 | - | - | 101 | 101 | 101 | false |
| 8 | - | - | - | - | 102 | 101 | - | - |
The final result is the same.
Ex 1 | LC 278 First Bad Version
[lo, hi):
1 | public int firstBadVersion(int n) { // available version: [1, n] |
Note: hi should have been n + 1, but will overflow if $n = 2^{31} - 1$. This is why people might not use [lo, hi).
To handle this, we can look into the problem to see if we can omit the plus one. For this problem, it is okay because if we process [lo, n) (equivalent to [lo, n - 1]) and the key is not found, it will return n which is the answer to the question. So there is no necessity to process n with extra code. If not found in [1, n), n will be returned.
[lo, hi]:
1 | public int firstBadVersion(int n) { // version: [1, n] |
If not found in [1, n], n + 1 will be returned.
Ex 2 | LC 69 Sqrt(x)
[lo, hi):
1 | public int sqrt(int x) { |
[lo, hi]:
1 | public int sqrt(int x) { |
Templates & Examples
Idea: Return lo means that lo is the least index such that g(mid) is true.
Left-closed Right-open Interval [lo, hi):
1 | public int binarySearch(int lo, int hi) { |
*Recursion version:
1 | public int binarySearch(int lo, int hi) { |
Left-closed Right-closed Interval [lo, hi]:
1 | public int binarySearch(int lo, int hi) { |
*Recursion version:
1 | public int binarySearch(int lo, int hi) { |
Ex 1 | No Duplicates
Return the index of an element in a sorted array. Elements are unique. If not found return -1. For example, A = [1, 2, 5, 7, 8, 12] and search(8) = 4, search(6) = 1.
Usage: int result = binarySearch(A, 8, 0, A.length - 1)
1 | public int binarySearch(int[] A, int val, int lo, int hi) { |
Or, we can modify the lower bound version to get the required result.
1 | public int binarySearch(int[] A, int val, int lo, int hi) { |
Ex 2 | Lower / Upper Bound
Return lower or upper bound of a value in a sorted array with duplicates. Since there are duplicates, we have two bounds for the duplicates.
lowerBound(A, val): First index ofisuch thatA[i] >= val, which is theg(mid)we mentioned above.upperBound(A, val): First index ofisuch thatA[i] > val(or the element not satisfying theA[mid] == val).
For example A = [1, 2, 2, 2, 4, 4, 5]:
lowerBound(A, 2) = 1(first occurrence),lowerBound(A, 3) = 4(does not exist)upperBound(A, 2) = 4,upperBound(A, 5) = 7(does not exist)
Note: #duplicate = upperBound(A, 2) - lowerBound(A, 2)
Lower Bound:
Application scenes:
- Array is sorted but contains duplicates.
- Array is partially sorted but does not contain duplicates.
- Array is partially sorted but contains duplicates.
1 | public int lowerBound(int[] A, int val, int lo, int hi) { |
Note: If the value does not exist, the method will return arbitrary values (-1 or hi + 1 etc.)
Therefore, when the requirement says if the value does not exist return -1, we need to use the following code:
1 | if (lo >= 0 && lo < A.length && A[lo] == val) { |
Upper Bound:
1 | public int upperBound(int[] A, int val, int lo, int hi) { |
Ex 3 | LC 69 Sqrt(x) with integer part only
sqrt(4) = 2sqrt(8) = 2
Conversion: Find the value m such that m * m > x then return m - 1.
Note: We can also use m > x / m to avoid overflow.
1 | public int sqrt(int x) { |
Ex 4 | LC 278 First Bad Version
It is an interactive problem. We can call isBadVersion(int version) at any time.
[lo, hi):
1 | public int firstBadVersion(int n) { |
[lo, hi]:
1 | public int firstBadVersion(int n) { |
Ex 5 | LC 875 Koko Eating Bananas
Find minimum K such that she can eat all the bananas within H hours.
Conversion: The eating speed K to the eating time H.
[lo, hi):
1 | public int eat(int[] piles, int H) { |
Ex 6 | LC 378 Kth Smallest Element in a Sorted Matrix
Each row and column are sorted.
[lo, hi):
1 | public int kthSmallest(int[][] matrix, int k) { |